Facebook
Facebook
 Reddit
Reddit
 Email
Email
This article explores the five best LLMs you can download with the LM Studio Application and then run on your PC / Mac.

AI is everywhere, and with the new Ghibli trend, people really seem to be embracing it. AI and its usage can be more than just creating Ghibli-style images. You can use this as a companion to help automate your garden, water it based on temperature, and even serve as your coding assistant, enabling you to implement complex algorithms in seconds.
You can use services like ChatGPT, ClaudSonnet, CoPilot Pro, DeepSeek R1, etc. However, you may be skeptical about your data leaking or if any third party is monitoring it. That is why most tinkerers love to run it locally. Now there is a catch: these models can really become resource-heavy. The minimum required to run the model with reasonable accuracy is around 12GB VRAM on any Nvidia / AMD GPU. With that said, let’s explore the options.
Disclaimer: We are using LM Studio to explore AI models; you can apply the same approach with Ollama. All the models mentioned here are available for download at Hugging Face.
Note – Community Models may produce content that can sometimes be inaccurate, offensive, or inappropriate for certain use cases. All models mentioned here have their GGUF quantization, provided by Bartowski based on llama.cpp. Please make sure to use these models responsibly and avoid unethical usage.
1. Gemma 3 (Google)
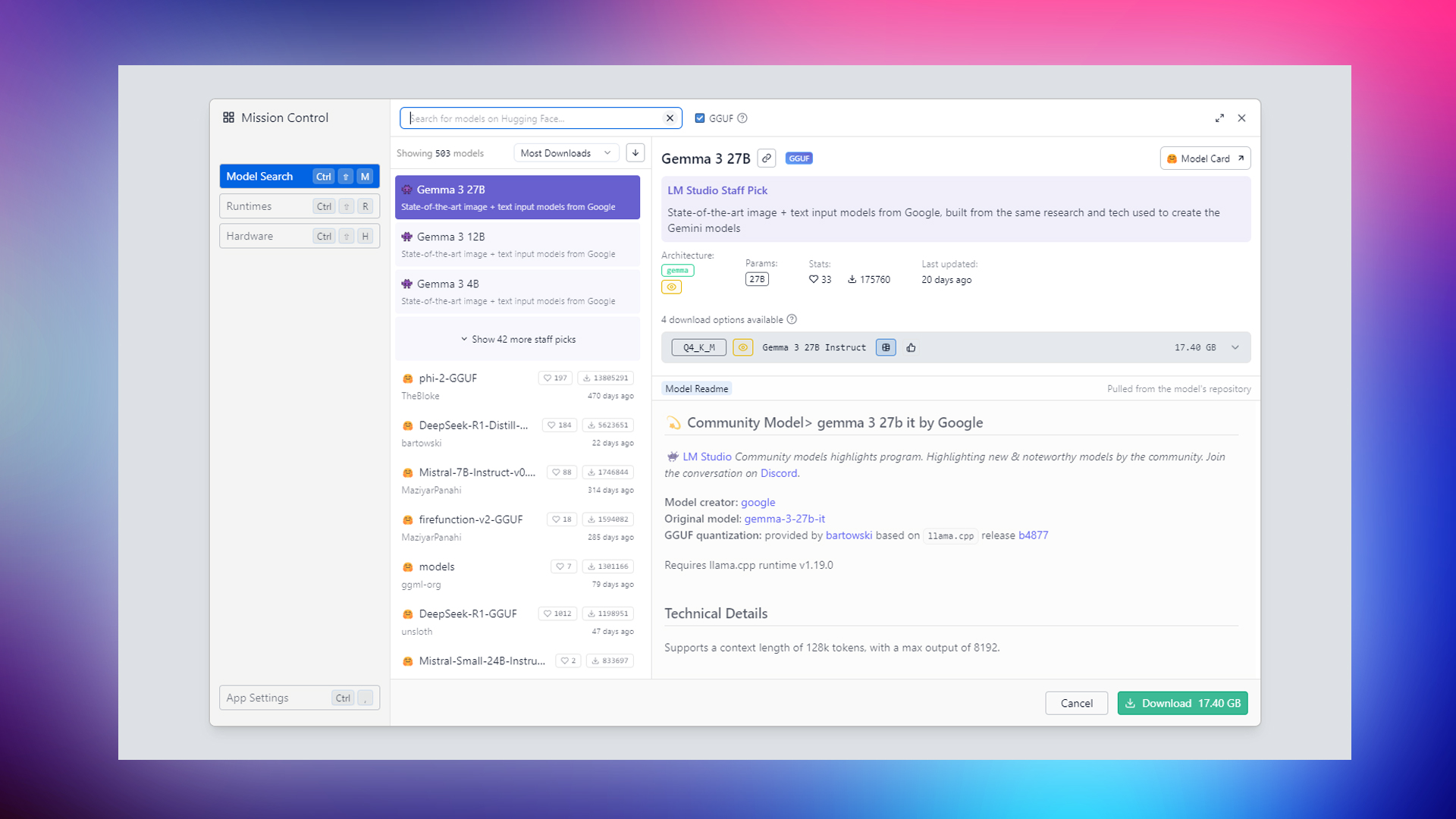
Google’s Gemma 3 is the latest LLM from Google. It is the number 1 trending in LM studio and has over 175K downloads. Users love this model due to its flexibility. You can run it on a Raspberry Pi with the 1 Billion parameter. But remember that the accuracy will not be the same as that of the larger models with higher quantization.
Key Features
- Multimodal capabilities (text + image) with a context window of 128,000 tokens.
- Strong multilingual support (140+ languages) and high performance on reasoning and vision tasks.
- Open-source availability with efficient deployment options, including GGUF and 4-bit quantized versions for local setups.
- Easy to run on any setup, with its parameters starting from 1B to 27B.
2. DeepSeek R1 Distill Qwen 7B
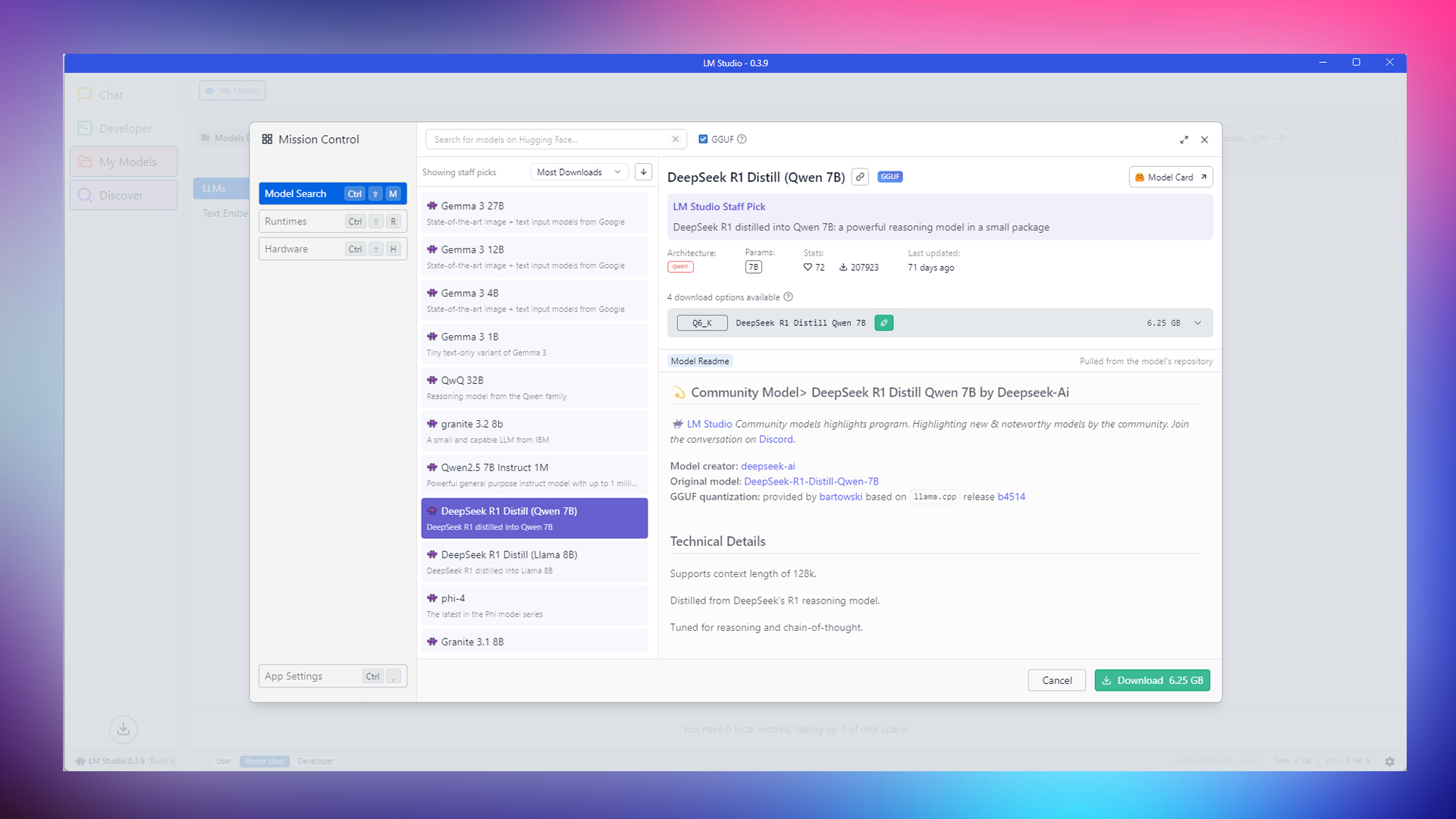
This iteration of the DeepSeek R1 is a community project powered by contributors such as Bartowski and Mr. Adermacher. This model is based on the llama.cpp release. The Qwen distilled version of R1 is tuned for factual reasoning tasks and coding. It also comes with various quantization settings. The concept is simple: the higher the quantization, the better the accuracy.
Key Features
- Supports context up to 128K tokens.
- Derived from the original DeepSeek R1-671b model
- Tuned for reasoning tasks and chain-of-thought processes.
- Excels in coding and mathematical reasoning.
- Uses Group Relative Policy Optimization (GRPO) for reasoning-focused learning.
3. Phi-4 (Microsoft)
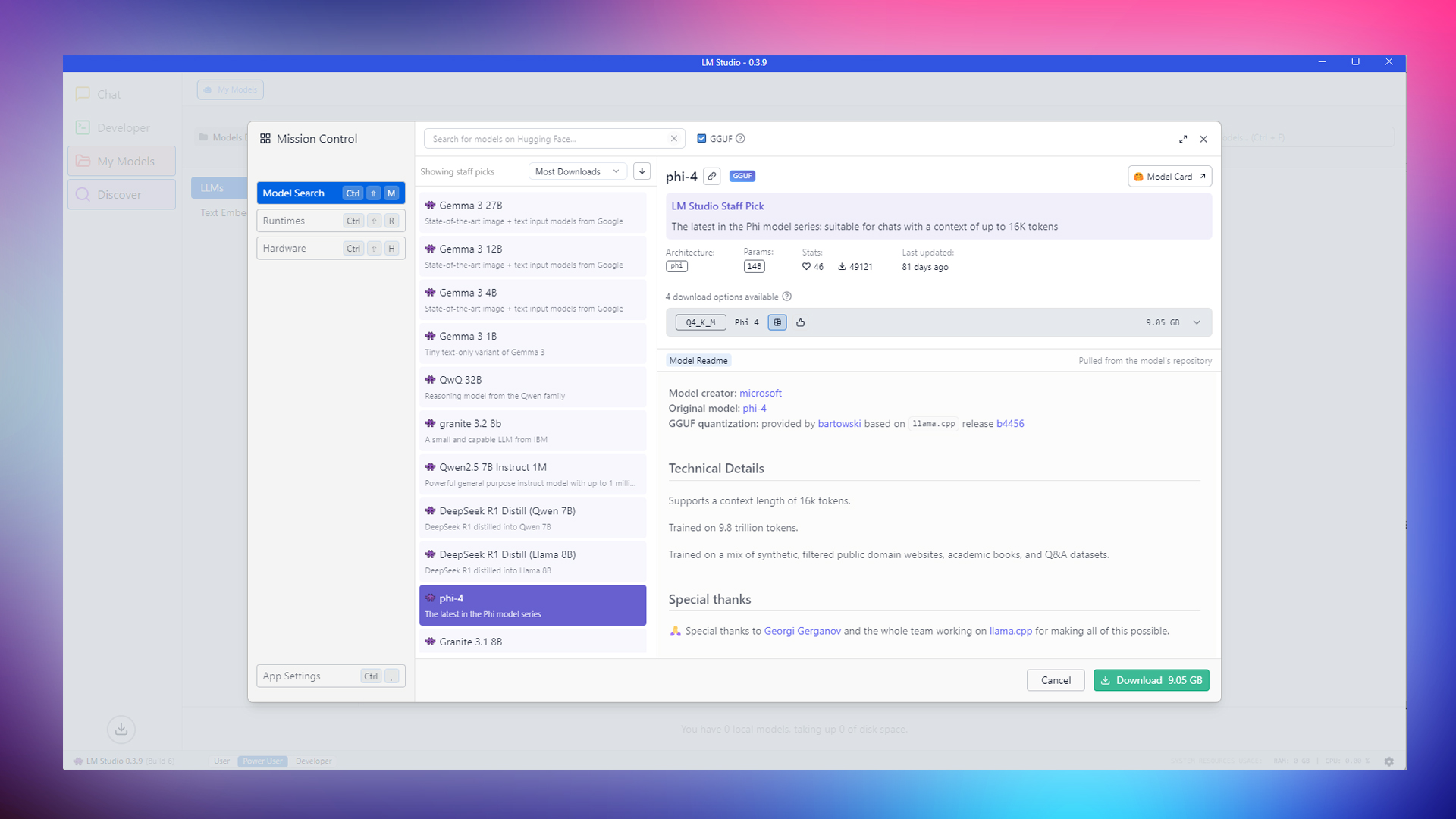
We all know the Copilot app on our PC; some like it, and others turn it off. Thanks to the community, we can run this locally without needing an active Internet connection. This iteration of Phi-4 is trained on 9.8 trillion tokens, and its data set includes synthetic data, filtered public domain websites, academic books, and Q&A.
Key Features
- Supports context up to 16k tokens.
- Processes text, speech, and visual inputs simultaneously.
- Efficient multimodal integration using LoRA-based techniques.
- Low computational demand.
- Optimized for reasoning tasks and chain-of-thought processing.
- Suitable for general-purpose applications, mathematical reasoning, and problem-solving.
4. Granite 3.2 8B (IBM)
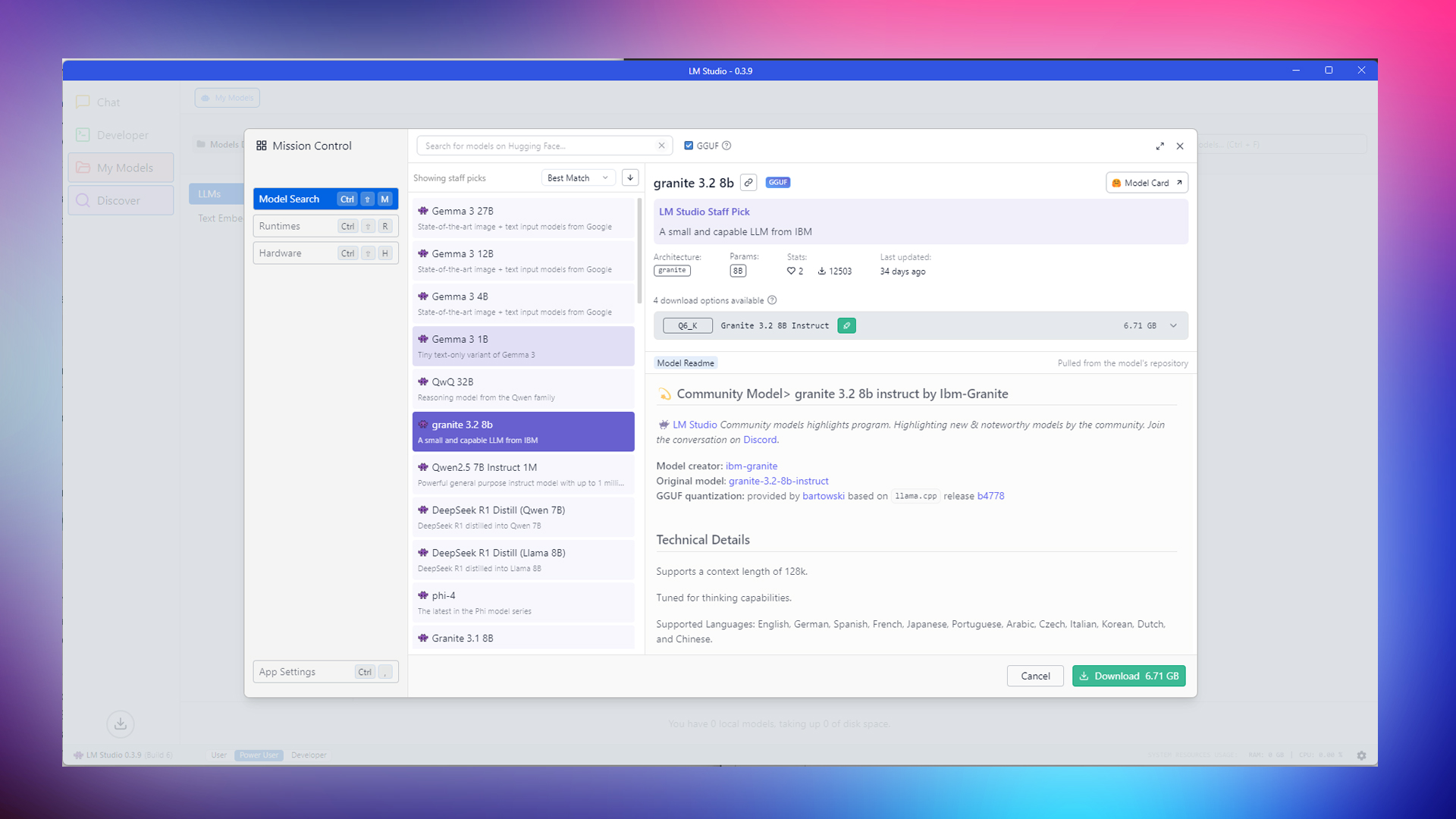
This iteration of the Granite 3.2 model is tuned specifically for thinking capabilities, emphasizing reasoning tasks and the chain of thought process. It supports English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, and Chinese Languages. Although the granite can be distilled down to the 2B parameter, the one most popular among the side models is the 8B.
Key Features
- Supports context up to 128k tokens.
- Vision-language model (VLM) capabilities optimized for document understanding tasks like OCRBench and DocVQA.
- Chain-of-thought reasoning toggle for efficient problem-solving without unnecessary computation.
- Suitable for enterprise-grade applications requiring high accuracy across diverse languages.
- Optimized for multilingual reasoning tasks and structured problem-solving.
5. QwQ-32B (Alibaba)
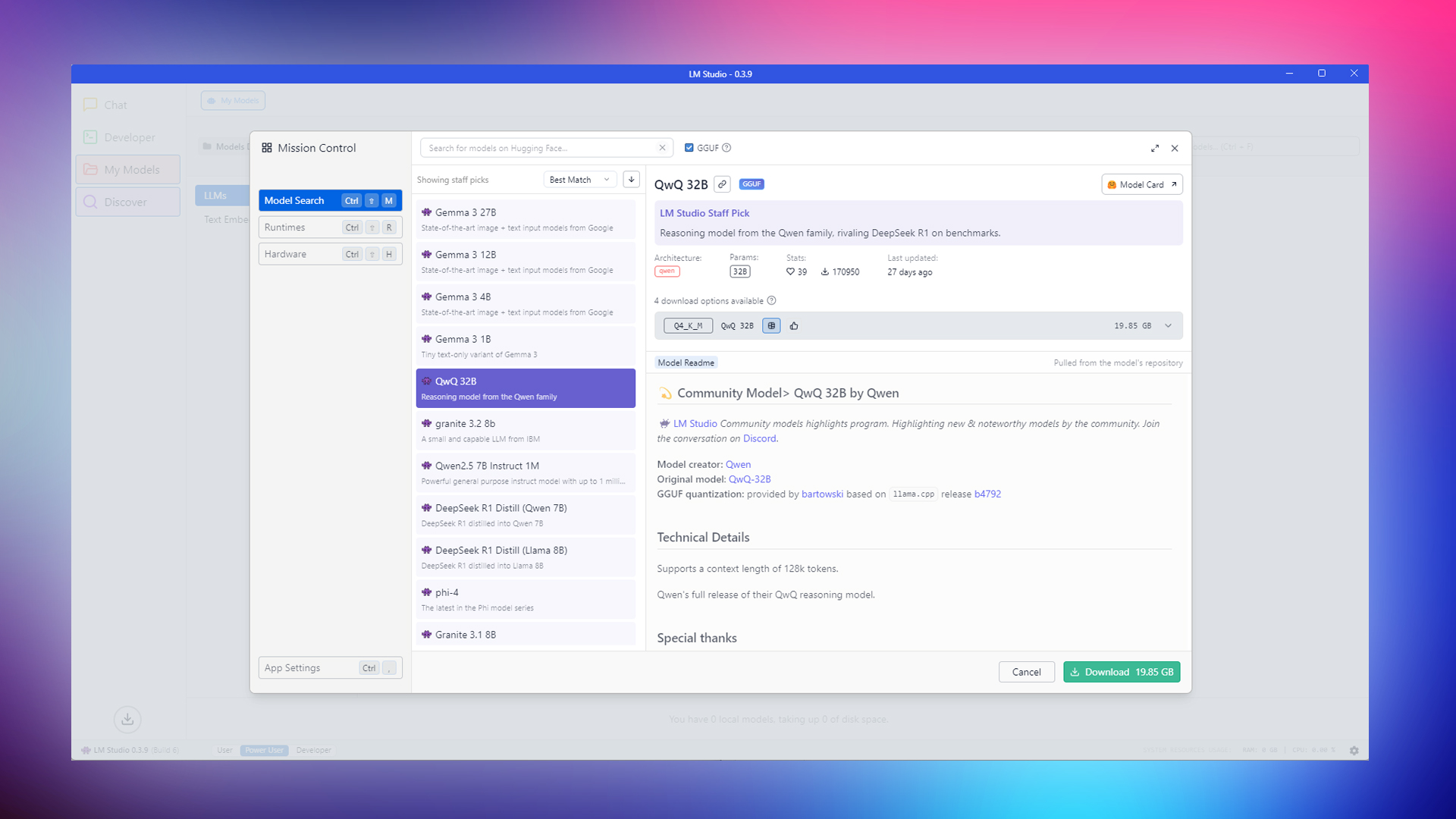
The Alibaba QWQ 32B is based on the Qwen 2.5-32B model. QwQ 32B is tuned to excel at intensive reasoning tasks, mathematical computations, and coding. Provided you have sufficient VRAM or System RAM, this can be a great companion to your coding setup (combined with continue.dev and VS Code).
Key Features
- Supports context up to 128k tokens.
- Reinforcement learning-driven training enhances reasoning, coding, and problem-solving abilities.
- Incredibly efficient with low computational resource requirements, even lower than DeepSeek R1.
- Excels in reasoning-heavy tasks, mathematical computations, and coding applications.
- Tuned for high accuracy across diverse benchmarks while maintaining efficiency.
Key Takeaways
- Again, please note that community models may produce content that can be inaccurate, vague, or unusable.
- LM studio is just a platform. LM Studio doesn’t directly make any of these. Community members have created these iterations of the original models.
- Please use these AI models responsibly and avoid unethical usage.
Looking For More Related to Tech?
We provide the latest news and “How To’s” for Tech content. Meanwhile, you can check out the following articles related to PC GPUs, CPU and GPU comparisons, mobile phones, and more:
- 5 Best Air Coolers for CPUs in 2025
- ASUS TUF Gaming F16 Release Date, Specifications, Price, and More
- iPhone 16e vs iPhone SE (3rd Gen): Which One To Buy in 2025?
- Powerbeats Pro 2 vs AirPods Pro 2: Which One To Get in 2025
- RTX 5070 Ti vs. RTX 4070 Super: Specs, Price and More Compared
- Windows 11: How To Disable Lock Screen Widgets